User Documentation¶
Getting Started¶
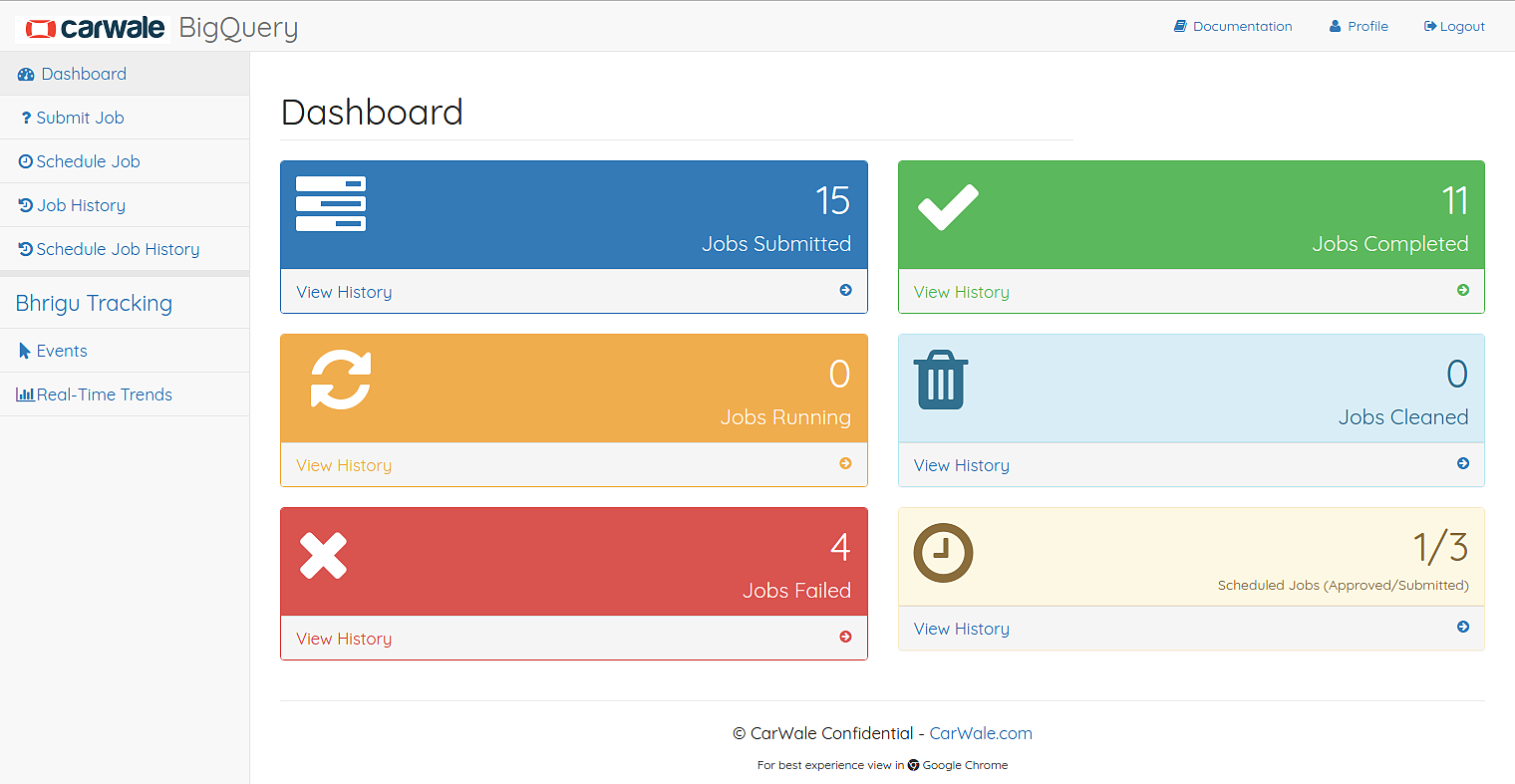
The Big Query system has some main features that will be described in detail below. Before that we’ll get familiar with the flow and nomenclature of the system.
Login¶
A CarWale associate can login to the system using their CarWale account credentials. Google authentication has been safely integrated with the system.

Note
By default a new user’s access will be blocked for security reasons. So, please contact system admin to grant usage access.
Overview¶
The general flow of using the system is
- Submit a query
- Query is sent to server and an ID is returned
- Query is queued and then processed
- Result is returned to the user
- This result can be viewed any time from the job history
After ad-hoc queries, if user wants to generate a recurring report, then he/she can schedule the job and this schedule request will be reviewed by the Admin.
Nomenclature¶
To get familiar with the UI, you need to understand some terms used in the system.
- Job
- Any query submitted by the user to the system is called a Job
- Job Statuses
- Queued: The job is submitted to the server and waiting to get processed in spark
- Processing: The job is being processed in spark
- Completed: The job is successfully processed and the result is generated
- Failed: The job has failed after execution
- Killed: The user has killed the job after submission
- Cleaned: The job result’s file stored on the server got cleaned
- Schedule Job Statuses
- Requested: The job is submitted successfully and waiting for admin’s approval
- Approved: The job is approved by admin and is ready to be executed on a schedule
- Rejected: The job is rejected because some is wrong with it
- Cancelled: The job has been cancelled from scheduled execution
- Resubmit
- The job will not be resubmitted instantly, rather is opens the Submit Job Page with the previous job data populated
- Execution Time
- The time taken for the job’s execution from the time of submission
Features¶
In this section we’ll discuss in detail the features of the Big Query system.
Submit Job¶
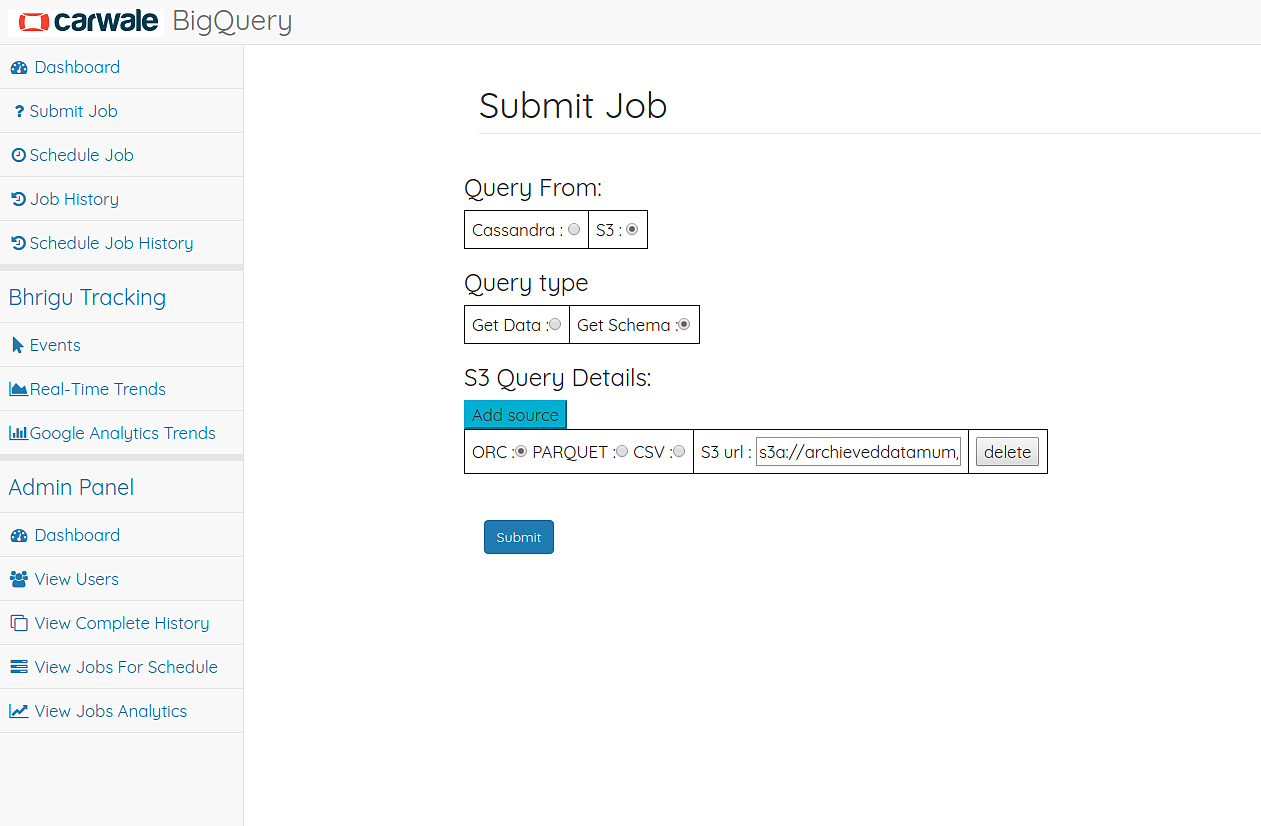
Submit Job Page allows user to get quick result for ad-hoc jobs. The result of the jobs will be stored in a file.
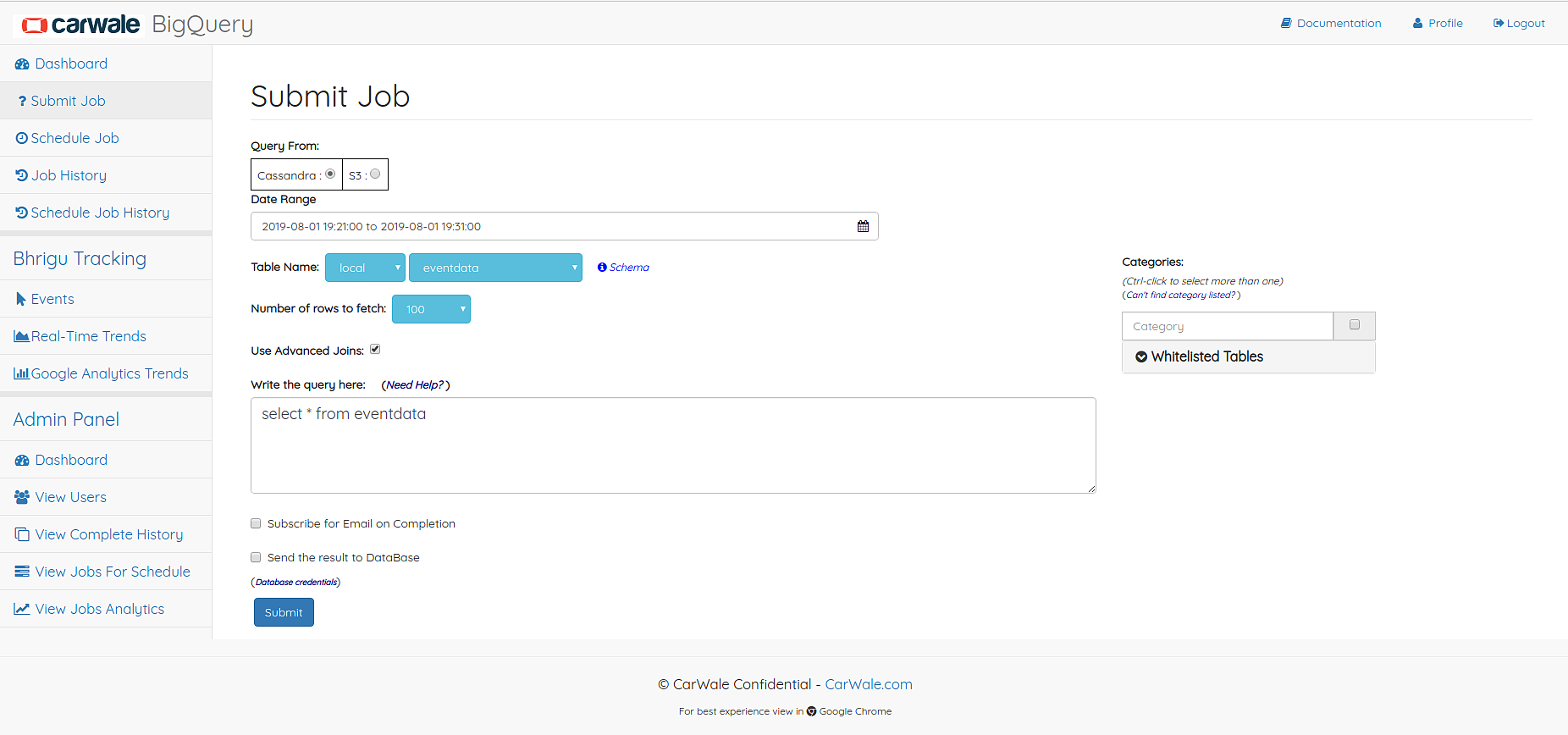
Submit Job Page
Procedure to submit a job
- Choose date time range
- Select cassandra table name
- Select number of rows to fetch
- Select the Categories on which you want to query (applicable only for eventdata table)
- Enter the query
- You can also use advanced join functionality for joining with some whitelisted mysql table.
- (Optional) Subscribe of email on completion of the job
- Submit the job
- Currently there is restrictions of 100000 rows can be fetched of any job. But if your output contains more than 100000 rows you could save the data in Databases given in the dropdown. Table in which you are dumping the rows should already exist in the database.
See also
See the restrictions
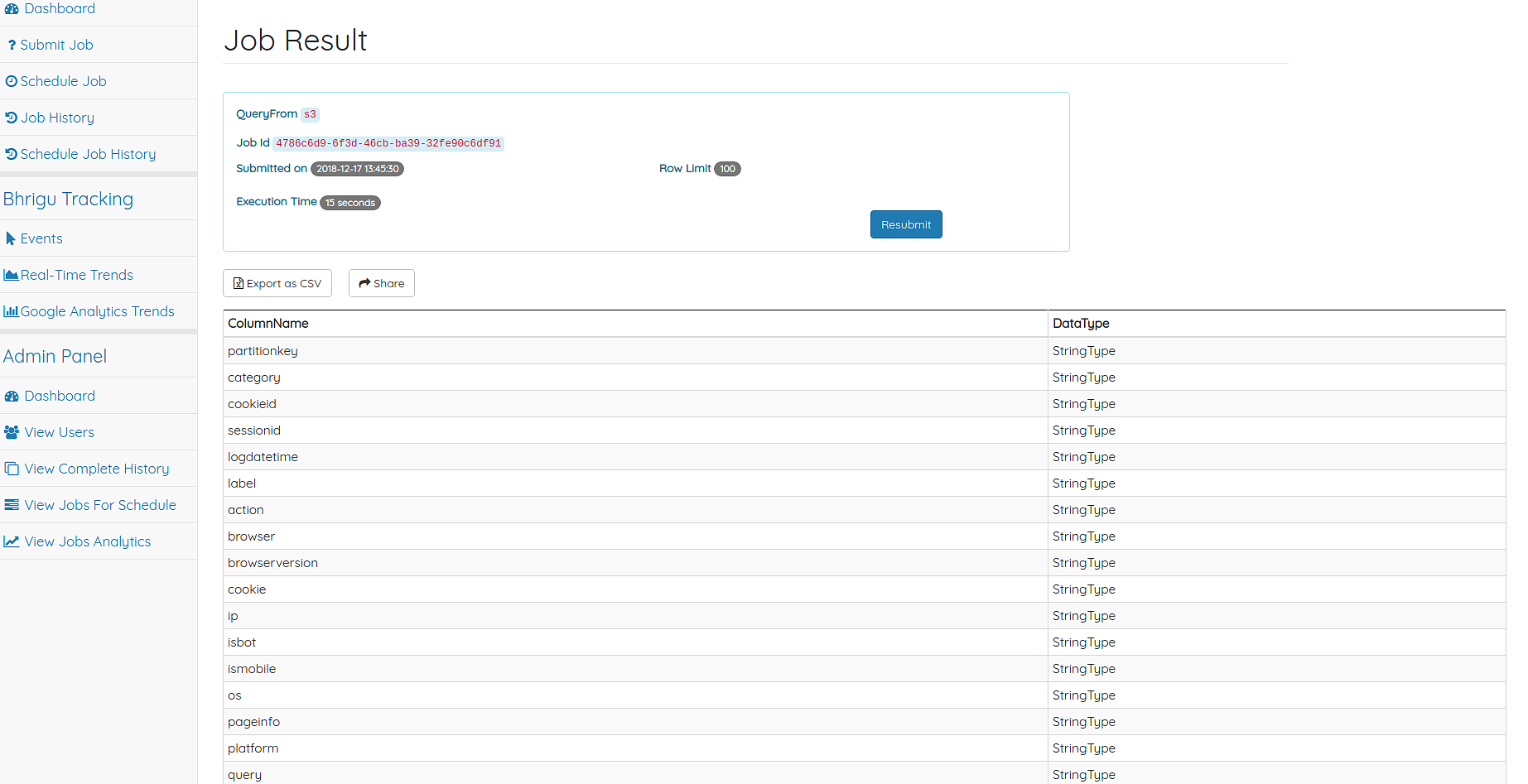
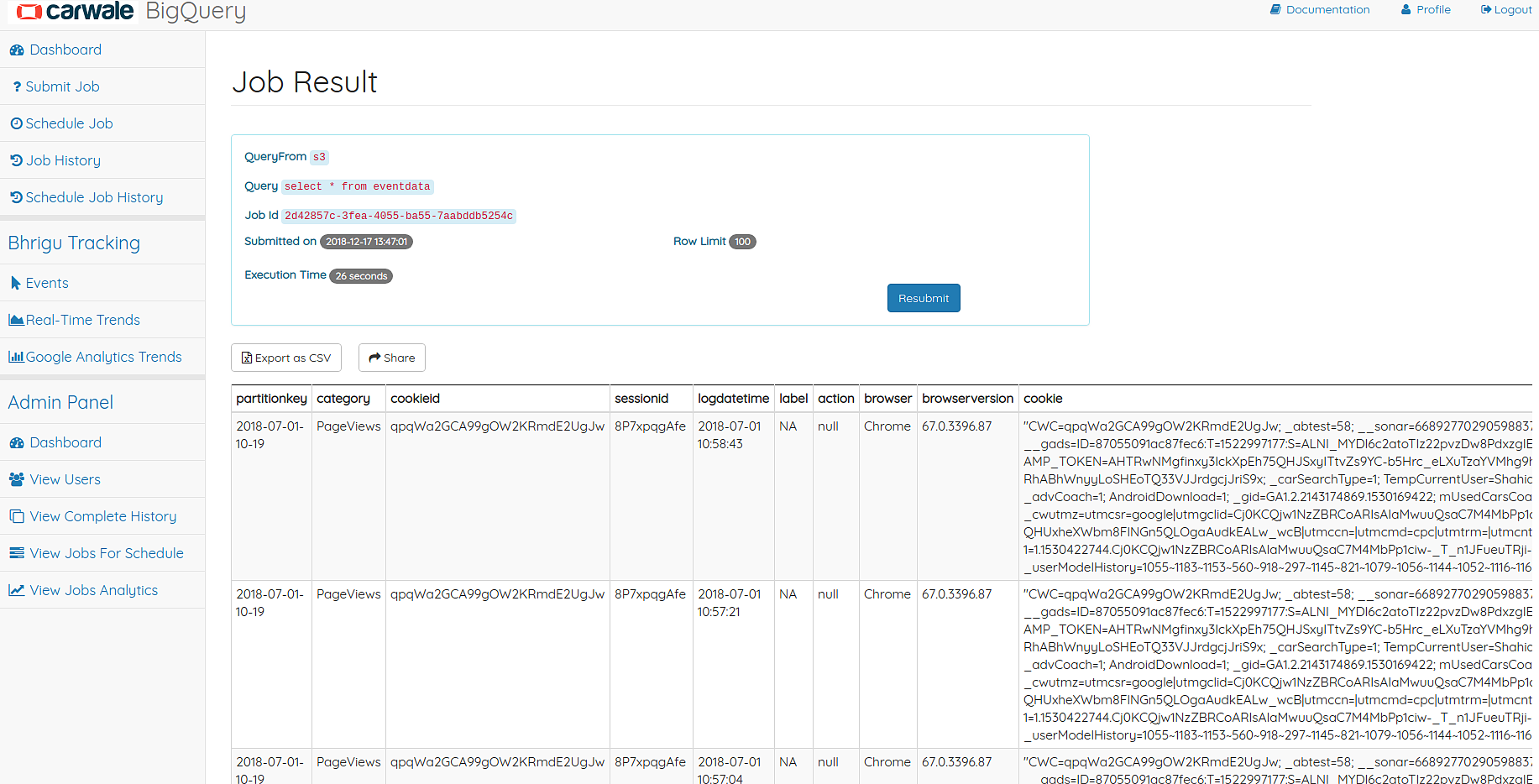
Job Result¶
This is the page where the result of the job is displayed.
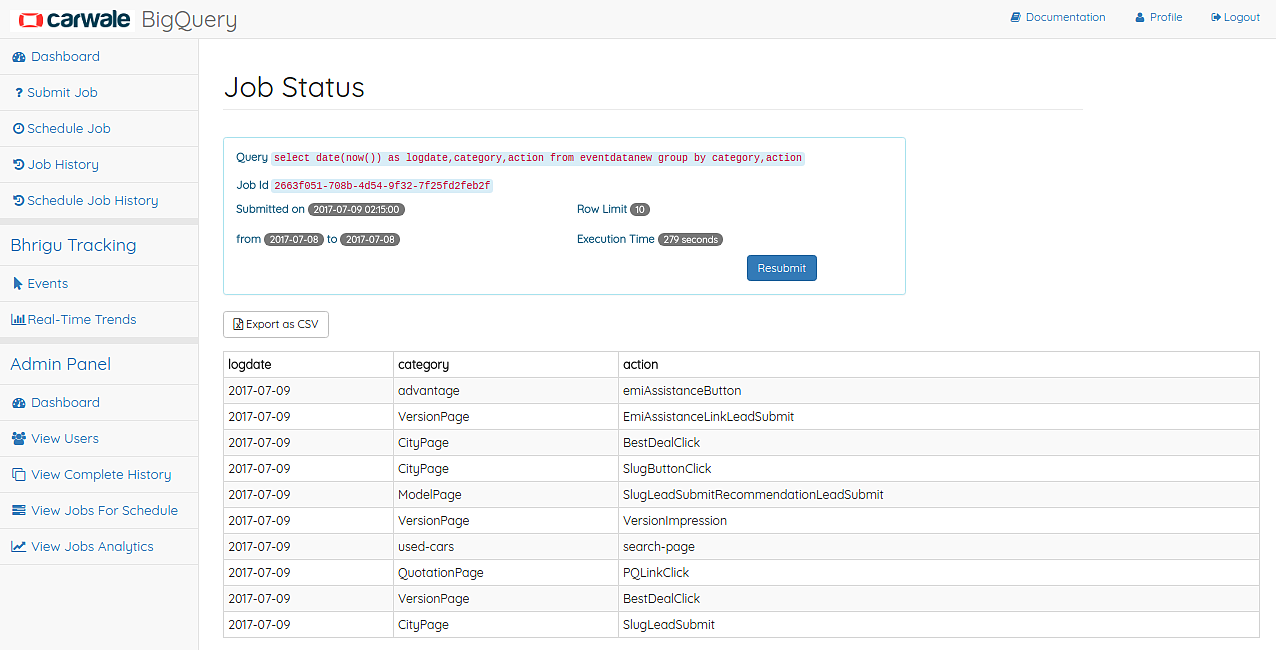
Job Result Page
For Completed jobs, the result is shown with pagination of 20 rows per page. The full job result can be downloaded in a CSV file. For Failed jobs, the page shows the error message to make correction in the earlier job. A Resubmit option is there for which populates the job details in Submit Job Page.
Job History¶
This page shows the history of all the jobs submitted by the user.
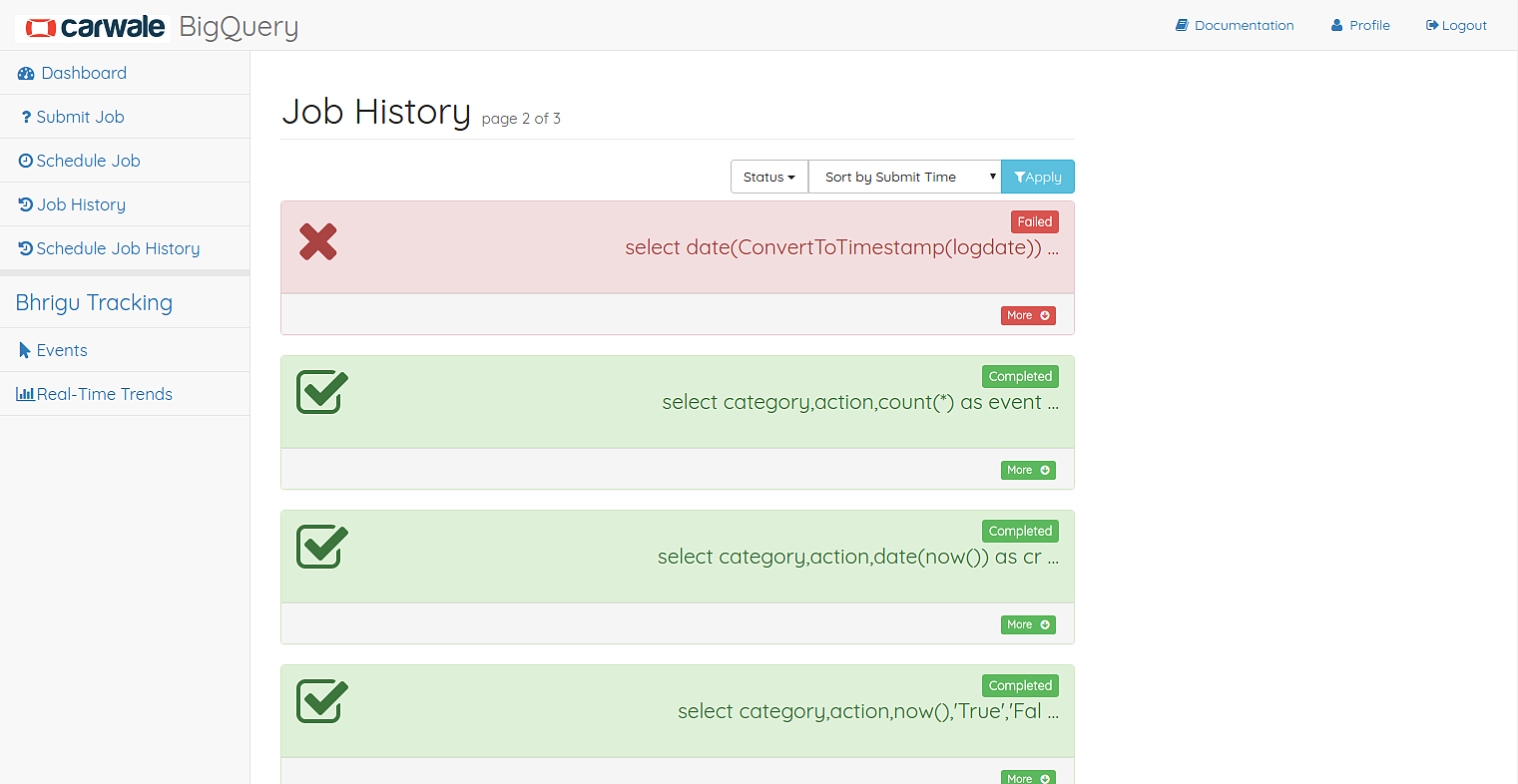
Job History Page
The user can filter the jobs based on the category(applicable on queries on eventdata table), status and also sort them using submit time or the execution time. Any job’s result can be viewed by clicking on the Result button corresponding to the job.
Scheduling¶
Job Schedule Page allows user to schedule recurring jobs and their result will be stored in Mysql database.
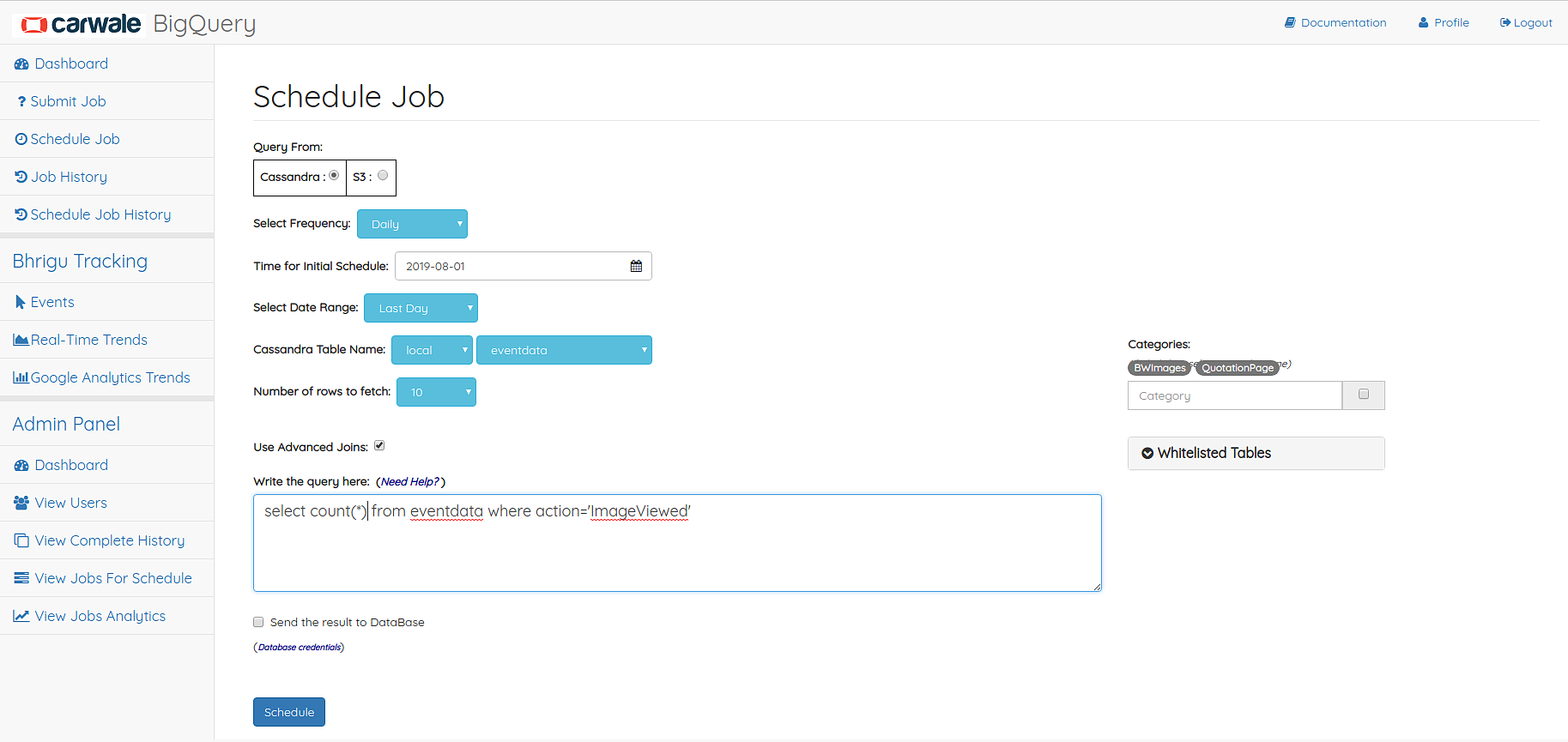
Job Schedule Page
Procedure to schedule a job
- Select the frequency of the job
- Select date for initial execution of the job
- Select relative date range for the data
- Select cassandra table name
- Select the Categories on which you want to run the job (applicable only for eventdata table)
- Enter the query
- You can also use advanced join functionality for joining with some whitelisted mysql table.
- (Optional) Select the DataStore in which you want to store the output of the job
- Select Database from dropdown.
- Enter table name: Enter existing table name
- Submit the job
User can view his/her schedule job history. The user can filter the jobs based on the status. And approved job’s execution history can be viewed by clicking on the Execution History button corresponding to the job. A sample result of 10 rows will be displayed in the execution history result page.
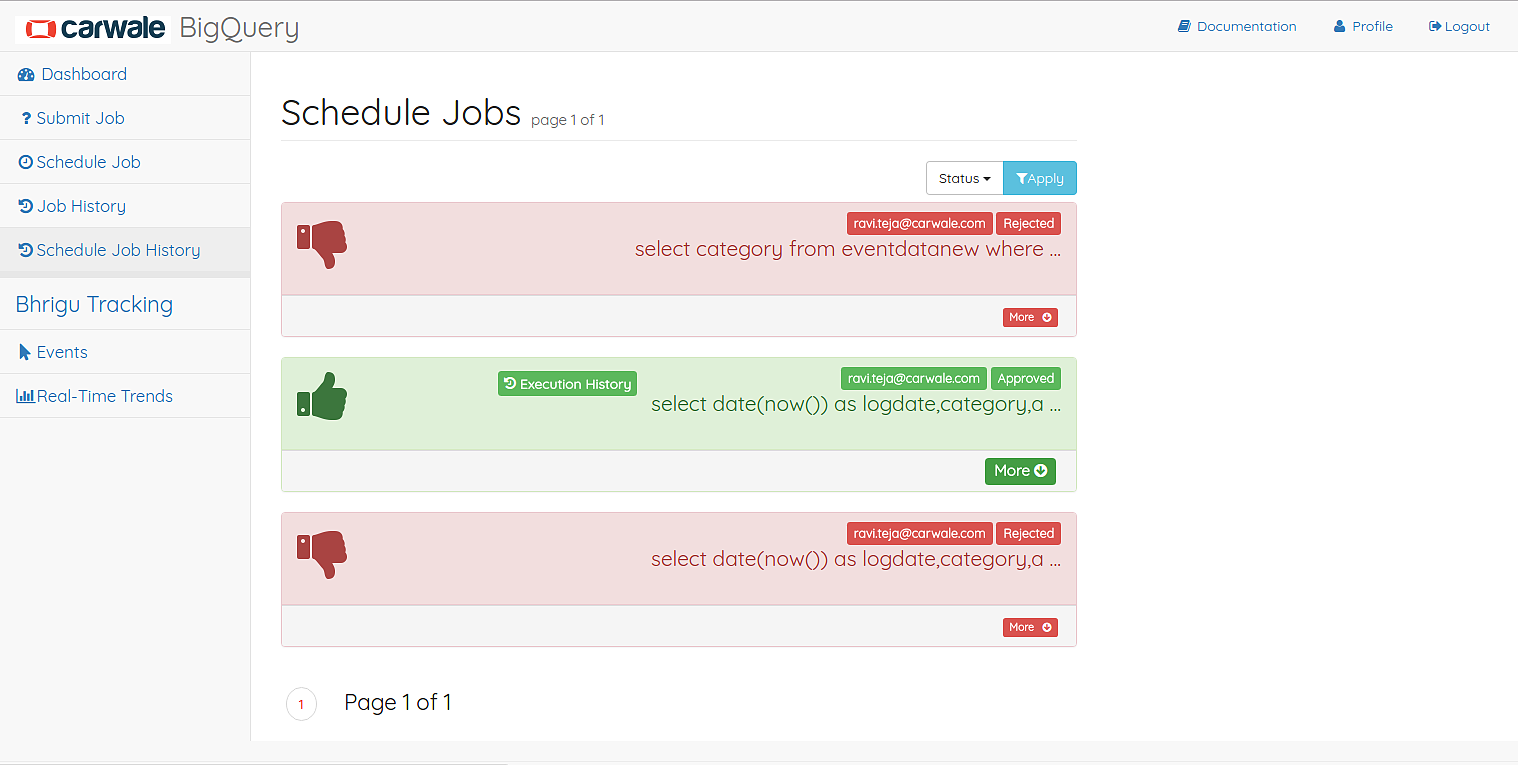
Schedule Job History Page
The user can view the remarks made by admin on any job by expanding the job tile in the page. He/She also can cancel the scheduled job.
Note
- The user will get an alert E-Mail if the job execution fails on any day
- The approved scheduled jobs run at 02:15 AM every day
Important
Credentials for Read Only access of the Default MySQL Data store are:
- DB Host:
10.10.3.70- DB Port:
3306- Database:
bigquery_datastore- UserName:
big.query- Password:
carwale
You need AWS VPN access to connect to this MySQL database. For other Data Store’s credentials please contact admin.
Admin Panel¶
The admin panel is for system admins to manage users, view all jobs submitted by the users and review the schedule job requests by all the users.
Querying¶
Job Query could be written in standard SQL syntax which will run as Spark Jobs, user does not need to worry about all the complexity involved in creating, running and managing Spark Jobs.
Supported SQL¶
Spark SQL supports the vast majority of SQL features, such as:
- SQL query statements, including:
- SELECT
- GROUP BY
- ORDER BY
- CLUSTER BY
- SORT BY
- All SQL operators, including:
- Relational operators (
=,==,<>,<,>,>=,<=, etc)- Arithmetic operators (
+,-,\*,/,%, etc)- Logical operators (
AND,OR, etc)- Mathematical functions (
SIGN,LN,COS, etc)- String functions (
INSTR,LEN,LOWER,REPLACE, etc)- Aggregate functions (
COUNT,AVG,SUM,MIN, etc)
- Joins and Unions
JOIN{LEFT|RIGHT|FULL} OUTER JOINLEFT SEMI JOINCROSS JOINUNION
- Sub-queries
SELECT col FROM ( SELECT a + b AS col from t1) t2See also
We could not cover all the available SQL functions here. Please visit this spark docs page.
Custom Functions¶
Apart from the SQL supported functions we have defined and registered our custom functions to ease out the extraction of data and perform operations. The custom functions are:
getpagetypeThis function takes input argument of page url and returns page type (ex: ‘ModelPage’, ‘QuotationPage’, etc)
Example :
select getpagetype(pageinfo) from eventdatanew where category='PageViews'
getvaluefromlabelThis function takes three input arguments of label string (ex:
key1=value1|key2=value2), key string and default value (this string is returned if specified key is not found). And this returns value corresponding to the key.Example :
select getvaluefromlabel(label,'make','NA') from eventdatanew where category='QuotationPage'
getvaluefromcookieThis function takes three input arguments of cookie string (ex:
key1:value1|key2:value2), key string and default value (this string is returned if specified key is not found). And this returns value corresponding to the key.Example :
select getvaluefromcookie(cookie,'_cwutmz','NA') from eventdatanew
getwebsiteinfoThis function takes one input argument of page url and returns website information (ex: ‘CW-MSite’, ‘BW-DesktopSite’, etc)
Example :
select getwebsiteinfo(pageinfo) from eventdatanew
datetimeThis function is useful to convert logdatetime column which is unix time to SQL Timestamp.
Example :
select date(datetime(logdatetime)) from eventdatanew
calculatetimespentThis function is useful to get timespent by the user on the previous event/page. This previous page can be accessed from referrer filed in the eventdatanew table.
Example :
select referrer, calculatetimespent(cookie) from eventdatanew where category = 'PageViews'
getmapfromlabelThis function can be used to parse label into a key-value map.
Example :
select getmapfromlabel(label) from eventdatanew where category='QuotationPage'
getvaluefrombigmapThis function is to retrive the value given a key and subkey from a BigMap
Map<String,Map<String,Int>>. This data structure has been used in userprofiling tables.Example :
select getvaluefrombigmap(userdata,'models','Nano',0) from userprofilesdaily
getstringfrommapThis function is to retrive a string value given a key from a
Map<String,String>. This is similar togetvaluefromlabel.Example :
select getstringfrommap(userpreference,'budgetsegment','NA') from userprofilesagg
getintfrommapThis function is to retrive a integer value given a key from a
Map<String,Int>.
Query from S3:¶
Now you can also query files stored on S3 which are of type orc or parquet or csv. There are two type of queries supported on s3, they are getschema and
getdata.
getschema :This will give you the schema of the data stored on s3 file.getdata :This will give you the result of the Query applied on the data.
Now lets look into each of them with little more explanation.
getschema
To get the schema of the data stored on s3, you need to provide the list of comma separated urls and the type of the files.
If you provide the more than one url, then result will be the combined schema of each file you have specified. Lets suppose you have provided
Twocomma separated urlss3a://path/to/file1,s3a://path/to/file2with columns[a,b]and[c,d]respectively and file type isorc.Then the resultant schema would be output of union of these two schemas i.e[a,b] U [c,d] = [a,b,c,d]Note
You can get schema of files of same type only i.e you can not get schema of file types
orcandcsvat the same time. If you provide multiple urls in comma separated format, then the type of all the files must be same. Otherwise it will throw an error.Get schema input page
- Get schema output page
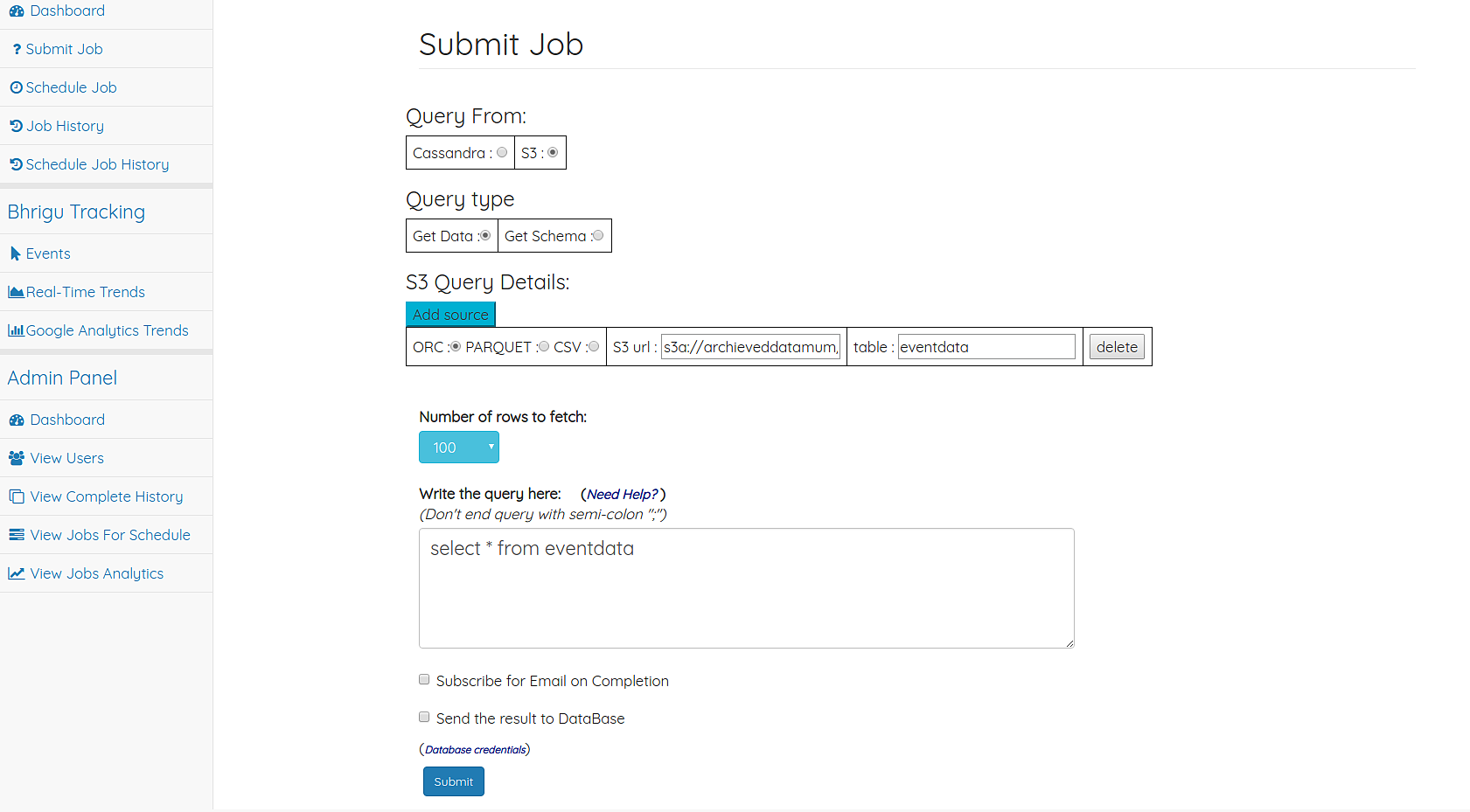
getdata
- To perform a sql query on data stored on s3, you need to provide
- urls :
s3a://path/to/file1,s3a://path/to/file2,s3a://path/to/file3list of comma separated urls.- file type :
orcorparquetorcsvtype of the files.- table name.
table01. A temporary table is created with the provided table name.- Query :
select * from table01. Query should contain the provided table name. Otherwise you would get error.Point two of getschema is applicable here also i.e Query would be performed on Union of schema.
- If you want to query from files of different type, then provide each of them as a separate input like below[From UI you need to add new source].
- files of type orc[source1]
- urls :
s3a://path/to/file1,s3a://path/to/file2,s3a://path/to/file3list of comma separated urls.- file type :
orc- table name :
table01. Temporary table with nametable01will be created.
- files of type csv[source2]
- urls :
s3a://path/to/file1,s3a://path/to/file2,s3a://path/to/file3list of comma separated urls.- file type :
csv- table name:
table02. Temporary table with nametable02will be created.- Query :
select * from table01 where somecolumn in (select colum1 from table02)- Query should only contain the table names provided, Otherwise you would get an error.
The type of the files provided in each source must be same. i.e You can not have files of type
orcandcsvin the same source.Note
You can aslo apply custom functions. i.e below sql query is valid.
select getvaluefromlabel(label) where category='somecategory'Get data input page
- Get data output page
Note
- Url of S3 file must start with
s3a://i.es3a://path/to/file- When Querying from multiple urls, provide them in comma separated format without quotes. i.e
s3a://path/to/file1,s3a://path/to/file2,s3a://path/to/file3
Restrictions¶
There are some restrictions as this system is not a relational database which supports pure SQL and the volume of data is huge:
- Can query on only 7 days event data in a single job (There are approx. 20 million rows per day and fetching such huge data for querying may crash the system)
- Cannot query on data older than 90 days (We archive the data older than 3 months and save it to
S3)- For data older than 90 days, you need to query from S3.
- Querying may take significant amount of time approx (5 mins for query on one day’s data)
offsetkeyword doesn’t work- If query is from cassandra, Cannot apply joins with other cassandra tables but whitelisted mysql table. However cassandra table self joins are feasible
- If query is from s3, You can apply joins with other tables.
- Cannot create tables or views
- Cannot index any columns