System Documentation¶
Architecture¶
The Architecture of Bigquery consists of three components
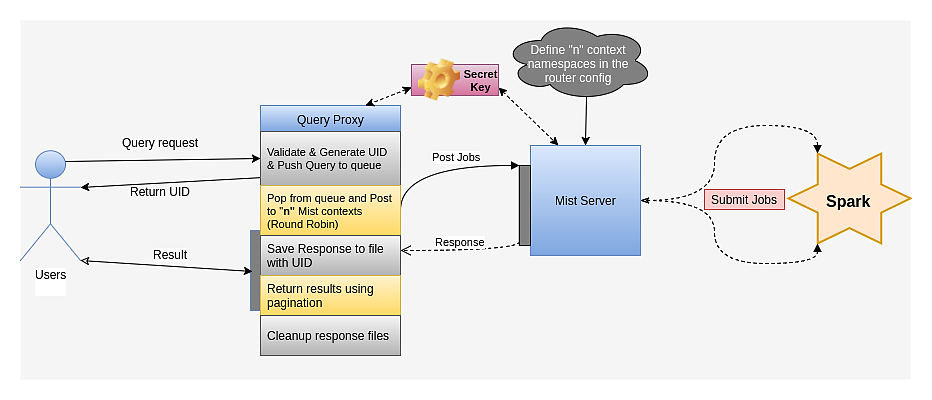
Query Proxy¶
Query Proxy is Most important component of our system, it acts as mediator (as the name Proxy suggests) between Web Application and the Mist Server.
It receives request from the user , validates and push the job request in queue along with returning Jobid to user, if queue is empty.
After getting responce from Query Proxy, it save responce to file named after the job Id .
When User request for result it will generate result using pagination and return result to ther user.
Query Proxy is also responsible for cleaning response files after certain amount of time.
Mist Server¶
Hydrosphere Mist is a Multi-tenancy and Multi-user Spark server.
Main features:
- Serverless. Get abstracted from resource isolation, sharing and auto-scaling.
- REST HTTP & Messaging (MQTT, Kafka) API for Scala & Python Spark jobs.
- Compatibility with EMR, Hortonworks, Cloudera, DC/OS and vanilla Spark distributions.
- Spark MLLib serving that has been moved to spark-ml-serving library and hydro-serving project
It implements Spark Compute as a Service and creates a unified API layer for building enterprise solutions and services on top of a big data stack.
Spark Cluster¶
Apache Spark™ is a fast and general engine for large-scale data processing
Spark Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
for more read the quick start guide here